The University of North Carolina at Chapel Hill’s (UNC-CH) Renaissance Computing Institute (RENCI) and Coastal Resilience Center (CRC) are making waves in Earth data science through their collaboration with the National Oceanic and Atmospheric Administration (NOAA). This partnership improves methods to assess and address coastal community risks by incorporating observations into the ADCIRC storm surge model to more accurately predict historical water levels across the Atlantic, Gulf of Mexico, and Caribbean coasts, increasing safety for the individuals living there. Recent acknowledgements highlight their pivotal role in advancing coastal safety and community resilience:
Coastal Ocean Reanalysis (CORA)
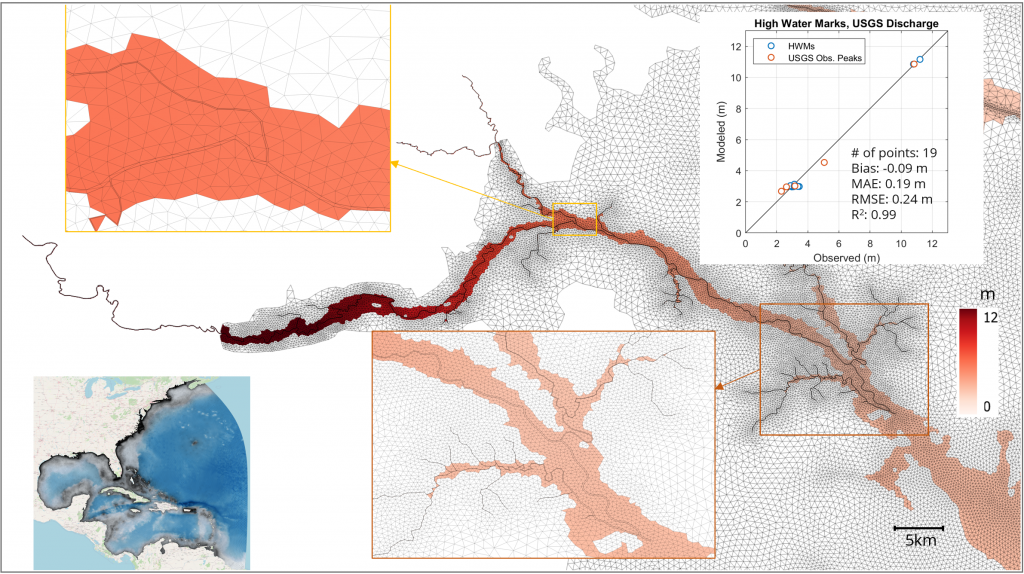
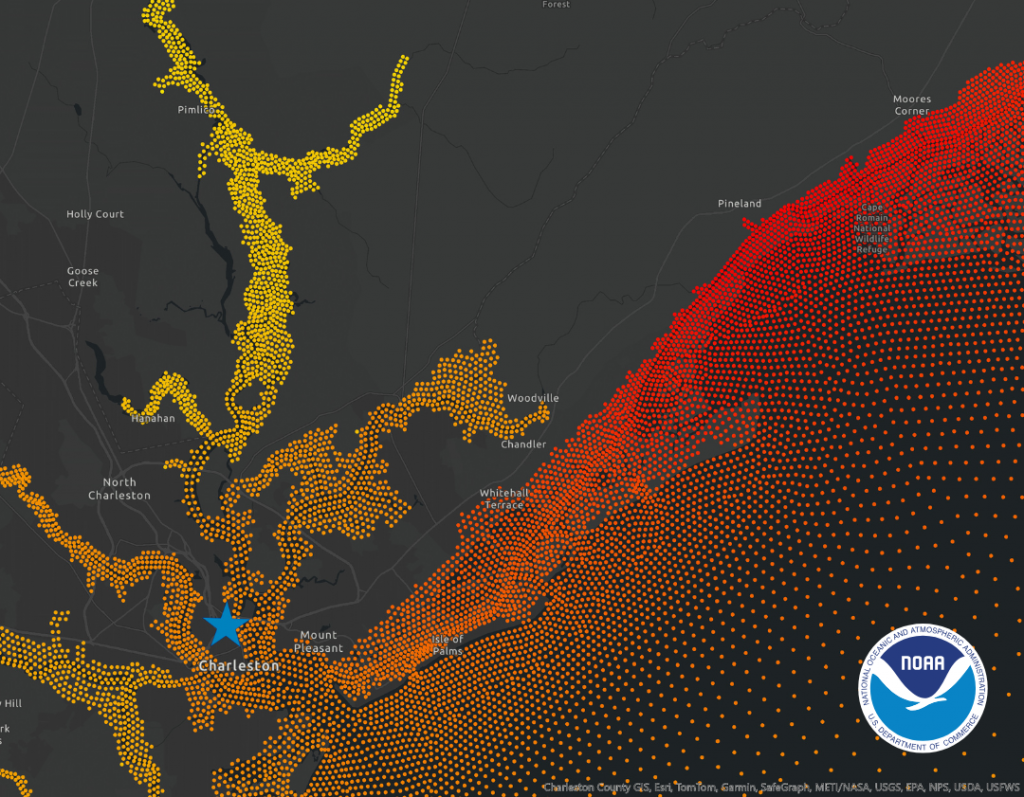
At the heart of this collaboration is the Coastal Ocean Reanalysis (CORA) dataset, a joint effort between teams from NOAA, the University of Hawaii, and UNC-CH. RENCI played a pivotal role by contributing its computational expertise to generate the new dataset. CORA provides predicted hourly historic water level and wave information at 500-meter increments along the coast, using observations dating back more than 40 years. Significantly, the model predictions, guided by observations, cover many areas where pre-existing data was sparse, capturing water level variability that will inform future assessments and needs in coastal regions.
Essentially, the data bridges gaps in existing coastal data, offering both precision and breadth to equip decision-makers with critical insights for flood risk and resilience planning and assessment.
CORA Gains Validation and Recognition
In June 2024, a NOAA article about CORA noted that researchers were able to provide preliminary validation for the dataset. A follow-up article in January 2025 noted that the publicly available (via NOAA’s Open Data Dissemination platform) dataset is already being used to address gaps in available data to improve coastal community flood risk assessment and planning. The article also notes that future uses of the dataset will enhance NOAA tools, like their Sea Level Calculator and High Tide Flooding Outlooks, as well as the National Water Model for comprehensive coastal flood mapping. Additionally, NOAA is looking to expand the dataset to include flood risk assessments for the U.S. West Coast, Hawaii, and Alaska by 2026.
In addition to these online accolades, during the 2024 American Geophysical Union (AGU) meeting, Dr. Rick Spinrad, Undersecretary of Commerce for Oceans and Atmospheres and Administrator for NOAA, delivered a keynote address celebrating NOAA’s many achievements. Among the highlights was the improved safety and awareness afforded to coastal communities thanks to CORA, a sentiment that was also published in NOAA’s 2024 Report, focused on how the agency was working to build a Climate Ready Nation.
Moving Forward
As NOAA continues to refine and expand CORA, the already vast applications will increase, improving coastal floodplain evaluations, supporting resilience planning, and offering decision-makers the ability to better protect their communities. By providing actionable insights into sea level rise and coastal inundation, RENCI and others involved in CORA are setting a new standard for improved climate resilience.